Working in a centralised SRE team tends to involve two kinds of work: engineering efforts, like rolling out a tool across the engineering org, and engagements where our expertise has been requested to help with a specific issue, such as helping with a scalability bottleneck.
When I worked in such a team, many development teams looked to us for assistance and guidance on a large set of topics: observability, incident handling, migrations, scalability, reliability, alerting. Of course, we documented as much as possible, and often pointed people to that documentation, but documentation is not the same as helping teams with their specific problems. However, we were always limited in the time that we had to engage with development teams. We used Production Readiness Reviews (PRR) as a method to share our production expertise efficiently with as many development teams as possible.
A Production Readiness Review is a process which assesses services’ operational capabilities and characteristics. PRRs are typically concerned with areas such as Observability, Reliability, Incident Handling, Scalability, Security, and Disaster Recovery.
I first encountered the term “Production Readiness Review” in the first Site Reliability Engineering book, which describes a PRR as “a process that identifies the reliability needs of a service based on its specific details”. Google SRE teams conducting PRRs consider:
- System architecture and interservice dependencies
- Instrumentation, metrics, and monitoring
- Emergency response
- Capacity planning
- Change management
- Performance: availability, latency, and efficiency
I used a process similar to Google’s PRRs while part of an on-call team which was responsible for incident handling. Services were developed and owned by other teams, so in order to onboard any service to our on-call list, we conducted what we called a 24x7 Handover review. The topics covered in these reviews were very similar to the ones in Google’s PRR process. The on-call team did not work closely with the development team to improve the service’s reliability — but we would still provide feedback and suggestions for how to improve the service.
Grafana Labs also uses PRRs. The goal of a PRR at Grafana is not for the reviewing team to take on a service, but rather to identify potential production issues, and reduce the “toil and risks that the product might face”. The topics examined during Grafana’s PRRs are essentially the same as those used by Google SRE teams.
All three organisations use a similar process to review a service’s operational capabilities, with the aim of producing more robust and reliable services.
One aspect of the value provided by PRRs is identification of risks and deficits in operational readiness. Identifying and improving in these areas should result in more robust systems. But we found there were additional benefits which derived from running PRRs. PRRs created opportunities to discuss operational topics, and how some practices work together. If we were working together with a team to improve, for example, Observability, we would help teams with identifying signals to monitor, alerting thresholds, and instrumentation. But within the scope of a PRR, we could start with a concrete failure scenario, and from there discuss system architecture, how their instrumentation would help them detect and manage the problem, and how to recover. PRRs helped us to show teams a more complete picture of system robustness.
Performing PRRs helped our SRE team understand whether teams were adopting the recommended practices, how SRE-provided tools were working, whether there were tooling gaps, and if new technologies were emerging that were not covered by the existing tools and practices. It gave us a valuable connection to the experience of the teams that we worked with and their operational capabilities.
This understanding of operational capabilities proved useful for other occasions. As well as using PRRs for launches of new systems, we began to use it to validate the preparation level of services critical for large commercial events. This use of PRRs was largely seen as a success: we would either find some blind spots where teams could improve, or we confirmed that the services were well prepared, which gave development teams and stakeholders added confidence.
When I moved to a new organisation, I found another use for PRRs: they gave me a structured way to assess the operational capabilities of services in my area of responsibility. By running PRRs with every team, I got to know their services, the operational maturity of each team, how different teams within the department were connected, what were the critical services of the department, and which operational aspects could be improved department-wide.
The steps, roles, and responsibilities for a PRR will also change from company to company. The following sections describe the process through which I ran PRRs across different companies, capturing the learnings from working with several teams, and multiple systems.
Performing PRR requires a review team and the development team for the system under review. The development team fills out a document with all of the information required from the system under review. After the document is complete, and a number of review sessions are held between both teams, the review team provides a list of risks identified during the review, with an indication of the criticality of each risk. It is generally up to the development team to decide whether and how to follow up on those risks.
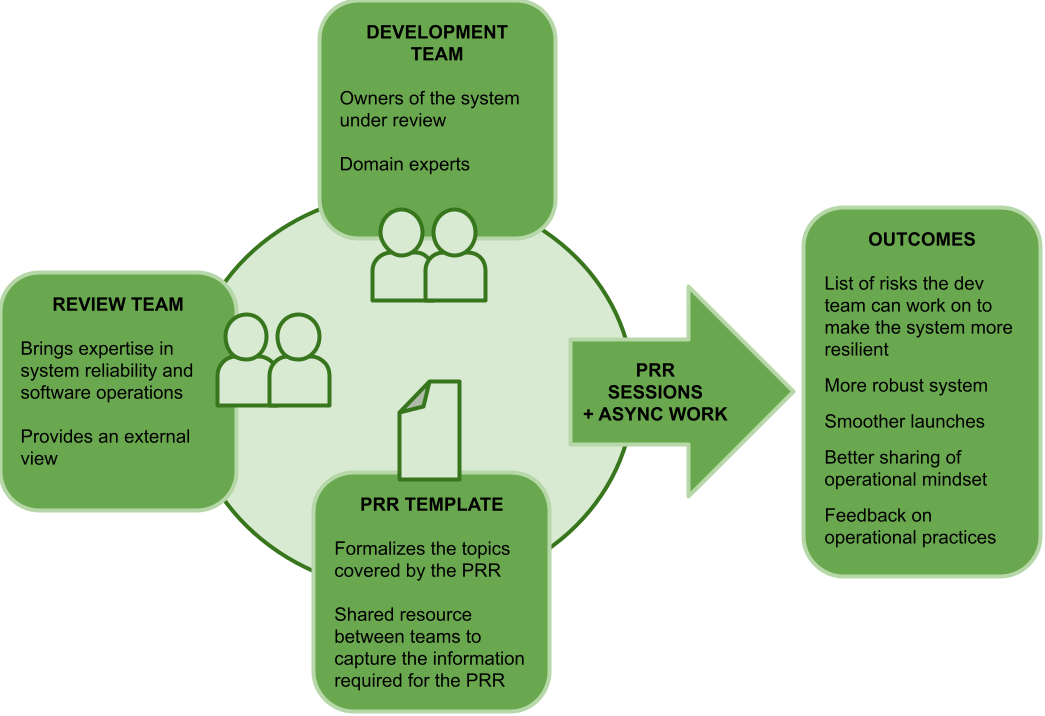
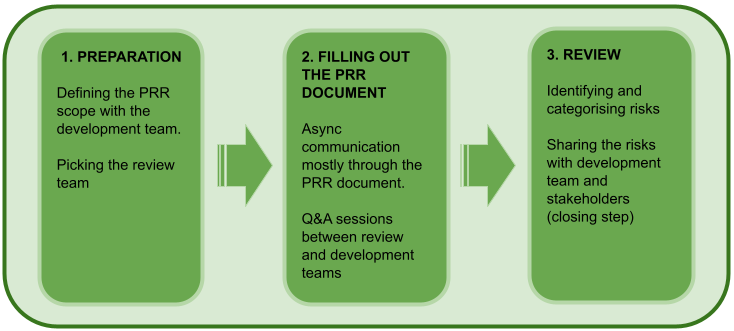
The PRR template is a document that lists the topics covered in a PRR, and the information that the development team needs to provide, typically in a questionnaire format. Creating the PRR Template requires a large one-time upfront investment, with the occasional update as the process matures, and the organisation changes. The PRR goes through three stages: preparation, filling out the PRR document, and review.
The scope of a PRR means what software components will be under review. One of the first questions that development teams usually ask is what should be in the scope of the PRR. Is it one service, or multiple? If it’s multiple, how many should be included? In most cases, the scope of the PRR should be a feature or product. In some cases, looking at services in isolation would be counterproductive, as those services don’t really work in isolation.
Let’s look at an example where a team just wrapped up development of a new product. The team that led the development of the new product requested the PRR ahead of the product’s go-live. The product was built on a microservices architecture. It relies on a few systems owned by other teams (not to mention any platform services). No development was needed from the other teams, as the new product is using only pre-existing features. In this situation, the PRR should ideally focus only on the new services developed for the new product. Dependencies owned by other teams should be out of scope for the PRR, although the client-server relationship will still be a part of it.
A PRR should only rely on a single document, regardless of the number of services included. By using a single PRR document it is easier for the review team to analyse the system as a whole, rather than looking at the individual components separately. This ‘big picture’ view grants the review team the ability to see how all of those new services interact to deliver their intended value, making it easier to spot risks that would be missed by looking at services in isolation. Filling out a single document is also a big help for the development team, because it will be less work for them, as some of the data collected for one service will be the same for some, or all of the others.
Creating the review template can be the biggest challenge in the preparation of the PRR process. It is a balancing act, where template owners need to cater to a broad set of topics to cover, accommodate for different system architectures (RPC, Frontend, Asynchronous, etc), being thorough enough to get all the information required to do a proper review, without going into too many details that would drag out the process and discourage development teams from doing PRRs. Below is a list of concrete topics that a PRR should cover, what to look for with each topic, and some example questions.
Context
Not an operational topic, but relevant to understand the placement of the system being reviewed in the company’s broader system.
- What product, or feature does the system deliver?
- Is it an internal, or externally facing system?
- What is the system’s criticality for the business?
- System architecture.
Observability
Make sure the team is tracking the relevant signals to understand the health of their system, and that those signals are of high quality.
- What signals are monitored?
- What dashboards the team uses?
- What telemetry types are used (metrics, tracing, logs)?
Alerting
If the system goes into failure, are there alerts that can notify the team in a timely manner, without the risk of alert fatigue?
- What alerts are in place?
- Is each alert accompanied by a playbook to facilitate incident handling?
- Are alerts connected to SLOs?
Dependencies
Understand the flow of data across the system and its dependencies. What other systems can impact, or can be impacted by the system under review.
- What dependencies does the system have?
- How critical is each dependency to the system’s purpose?
- Discussing reliability practices and their configuration.
Data Management
Know what data is the system storing, and how the team manages those data stores. Discuss caches, and their eviction policies. Databases, and what level of replication, or sharding is being used.
- What data stores does the system use?
- Are there backups, and is the team aware how to restore from a backup?
- Is the system using caches, and what kind of eviction policy do they have?
Security
Learn how the system protects its data, and how it guards itself against bad actors.
- Is access to the system granted only to authorized users?
- Is PII data properly secured?
Deployments
The method to deploy the components of a system can present some risks. A deployment could risk overloading other systems, or have a dependency that would block a deployment.
- What are the steps required to deploy the different components of the system?
- What is the deployment mode (canary, blue green) for those components?
- What kind of testing is executed with each deployment (e.g. end-to-end tests)?
- What signals indicate a successful, or faulty deployment?
Scalability
Validate that the system is appropriately sized, and can handle spikes in load without being overloaded, or overloading neighboring systems.
- How does the system scale?
- Were load tests executed?
- What resources (memory, CPU, dependencies, etc) typically present a bottleneck for the system?
- How does the system protect itself from being overloaded (rate limiting, load shedding)?
Failure modes
Discuss the ways through which the system can fail, what resilience is built into the system to handle those failures, and how the team would react to said failures. This is often a source of valuable insights, but also where teams often need more guidance.
- What are the failure modes of the system? How are they mitigated?
Being presented with a long template full of questions, many of which may not apply to the system under review, can be quite off putting for the development team. Going into too many details also risks overlap and repetition, which can delay filling out the template, can increase confusion, frustration, and diminish the potential benefits of the PRR. In short, we need to balance information gathering, with the effort required to fill out the template.

In my experience, the model that works best is to have a template that covers every area, but without going into too many details, meaning the template does not become too long. During the review, reviewers have the chance to dive deeper in areas where they believe to be relevant (i.e. where they see a potential for higher risks). It should be noted that this places a bigger burden on the review team, as they require a certain level of experience to be able to spot the areas where deep dives are required. This burden can be minimised by separately documenting guidance to help reviewers with those deep dives.
Let’s go through an example concerning reliability patterns (retries, fallbacks, circuit breakers, timeouts). Below we have 7 questions that go into increasingly higher levels of detail.
- “Do you use reliability patterns (retries, fallbacks, circuit breakers, timeouts)?”
- “Which reliability patterns (retries, fallbacks, circuit breakers, timeouts) are used in the system?”
- “Which reliability patterns (retries, fallbacks, circuit breakers, timeouts) are used in the system, and where are they being used?”
- “Which reliability patterns (retries, fallbacks, circuit breakers, timeouts) are used in the system, where are they being used, and how were they configured?”
- “Which reliability patterns (retries, fallbacks, circuit breakers, timeouts) are used in the system, where are they being used, how were they configured, and how did you arrive at those values?”
- “Which reliability patterns (retries, fallbacks, circuit breakers, timeouts) are used in the system, where are they being used, how were they configured, how did you arrive at those values, and how are you monitoring whether these patterns are being activated?”
- “Which reliability patterns (retries, fallbacks, circuit breakers, timeouts) are used in the system, where are they being used, how were they configured, how did you arrive at those values, how are you monitoring whether these patterns are being activated, and do you have automated tests in place to validate that they work as expected?”
It is fair to say that the first question is rather superficial. It’s a ‘yes or no’ question, with plenty of room for risks to remain unnoticed. I would also argue that the last question is the one that really provides you with all the information you need to gauge if reliability patterns are being correctly applied. Very often, when we asked about circuit breaker, or timeout configurations, teams would admit to simply using the library’s defaults, without consideration for the performance of the service being called. Asking this question often drove the development team to revise their settings. If we want to maximise information gathering, it makes sense to include the last question in the template.
But we also need to account for the effort required from the development teams. In a system with one or two dependencies, it shouldn’t take so long to gather that data. However, the same cannot be said about larger, more complex systems, with multiple dependencies (internal or external). Also consider that it is unlikely that all of those dependencies are equally important, and as a consequence, not all will be equally deserving of the reviewers’ attention.
For every topic, the level of detail you will pick will depend on your situation. You will need to consider the experience of those that would be your reviewers (could they reason through the data they would receive?), the engineering maturity of your organisation (would they be able to understand what is being asked, without significant support?), and the topic itself (is there enough depth in the topic for the PRR to go into? - An example: If teams only deploy applications via the company’s internal tooling, there won’t be much to learn from a deep dive into deployment tooling).
Regarding the different architectures that can be under review, my recommendation is to ‘modularize’ the template. Identify which questions are independent of the architecture, which ones could have different interpretations depending on the architecture, and which ones are specific for a given architecture. The latter group you can break into their own sections, so that development teams can quickly skip them when filling out the template.
The one thing to keep in mind is that it is not critical to get it right the first time. You can, and should, iterate on the template. Listen to feedback from your peers, and from the teams that go through the PRR process. Very often, between rounds of PRRs, we made changes to the PRR template (big or small), and your experience with PRRs should not be different.
The broad set of topics covered in a PRR already informs some of the ingredients expected of the review team. At the bare minimum, reviewers will have to be knowledgeable in those topics. But there are other ingredients to consider, coming from the system under review. For example, if the system employs an asynchronous architecture based on message queues, at least one of the reviewers should be familiar with that architecture; if the system uses a NoSQL datastore, reviewers should be able to reason about the NoSQL paradigm.
To maximise the potential to identify risks, and remove biases, reviewers should be external to the team. Some degree of familiarity with the domain can be helpful, though.
In terms of review team size, two reviewers tends to be the sweet spot. It makes it easier to cover all the topics of the review without a single reviewer having to be knowledgeable in all of the areas, while also making it easier for a reviewer to notice something the other reviewer may have missed.
Larger groups of reviewers are not advised. The bigger the group, the bigger the logistical difficulties. For starters, you will have to find more people to conduct reviews. It’s harder to get everyone together, and more people can prolong the process as it is more likely to result in longer discussions, and can make it harder to agree on a set of risks and recommendations.
Reviewers as a potential bottleneck for PRRs
When trying to adopt the PRR process in an organisation where the SRE team owns the process and is the only source of reviewers, that team can easily become a bottleneck for the process. There are two situations where this could happen: the process is in high demand; or, some event drove the team to run PRRs for multiple systems at the same time. In both cases, you will quickly run out of SREs to review all of the systems, making PRRs a full time job, and development teams waiting for a long time for their system to be reviewed – and remember that those teams could be on a deadline.
To avoid becoming a bottleneck, identify other potential reviewers in your organisation. If there are Staff+, then these would be good candidates to review PRRs. In the absence of Staff+, or if the number of Staff+ engineers is also low, look for Senior Engineers with an operational mindset. This could be a great growth and knowledge sharing opportunity for any that participate.
The number of meetings between the reviewing team and the development team will depend on the complexity of the system under review, and the experience of the development team. Two to four sessions is typical in my experience.
Outside of these joint working sessions, most of the work in the PRR will be asynchronous. It can be efficient to work in a collaborative document, where those involved can tag others, write comments, notes, and ask questions. You can also set up a channel for an on-going asynchronous collaboration between review and development teams.
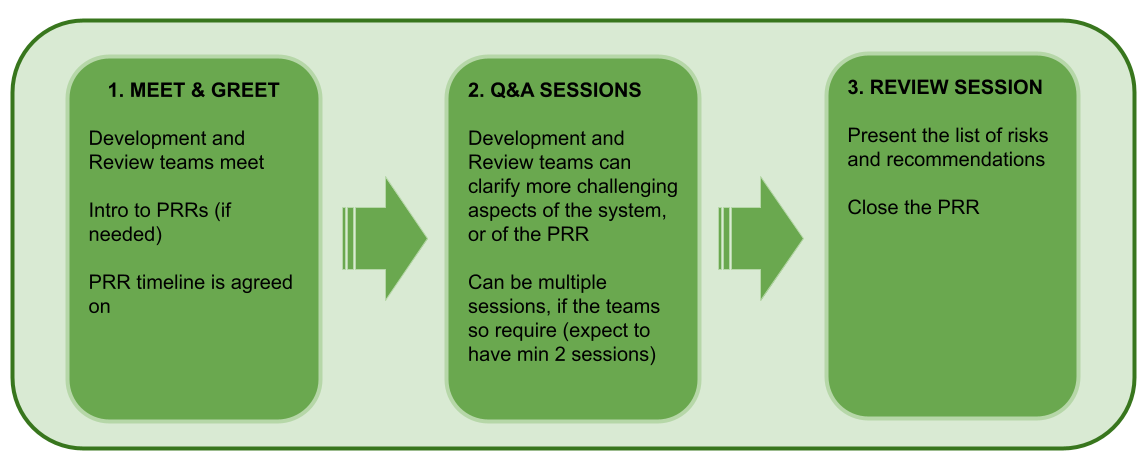
The first session will be a Meet & Greet with the development team. To nudge things along, in the invite for the first session include the following elements:
- Introduce the review team members.
- Links to any documentation about the PRR process.
- A link to the template while encouraging the teams to already have a look, and possibly filling out what sections they can.
Use this session to do a walkthrough of the process and the template for teams doing this for the first time. Teams more familiar with PRRs, however, may already come with the template partially filled out.
Arguably, the most important part of the first session is to make it clear for the development team that the PRR is for their benefit. Clear any misconception that the review team is some sort of gatekeeper, and emphasize that you are working together with them to make sure that whatever they are looking to launch will be a success.
In this session establish a timeline for the PRR execution to keep things on track, and conduct a timely review. Schedule in advance the sessions you think will be necessary. This will help the team keep up the pace, while preventing the PRR process from dragging on. When deciding the interval between sessions, consider how familiar or foreign the system‘s domain is to the reviewers (the more foreign, the more clarifications the reviewers will need), and also the complexity of the system under review.
The Q&A sessions are useful for both review and development teams. In these sessions, the development team can clarify some unclear aspects of the template. For the review team, Q&A sessions are valuable to address more challenging aspects of the system under review, where channel or document comments are not well suited to provide clarifications. Expect to have at least 1 to 2 Q&A sessions.
When the development team has added all of the relevant information in the template, and the review team has clarified any open points, the review team will have all the data it needs to finalize the list of risks. That list should include: what risks were identified; their criticality; recommendations on how to address the risk
That list will then be presented in the final Review Session. In this last session, both development and review teams will have the chance to go into more details on the risks, their impact, and the recommendations. After the final review session is done, share the review outcome by email with the development team, as well as their leadership. This email will mark the end of the PRR process.
In my experience, most risks will be easy to handle, particularly in organisations with mature engineering practices. Occasionally, some more critical risks will be identified (like single points of failure without resilience or mitigation strategies, or potential to overload neighboring systems). On very rare occasions – but it has happened – it should be made abundantly clear to the development team that the system under review should not go live at all, until a considerable redesign has taken place. In this last case, it makes sense to have a more direct approach to the development team’s leadership. When escalating to management, the message should be carefully crafted to avoid any undesired consequences for the development team. Handle it like you would a postmortem, and adopt a blameless tone.
If you are conducting many PRRs you can spot patterns of operational challenges across multiple systems, and tech stacks. You can then take those patterns and use them as input for your organisation’s tech strategy, in order to address those challenges. Common challenges that come to light are observability gaps; misconfigured retries, rate limits and timeouts; and insufficient data recovery and disaster recovery planning and preparation. You may also find documentation issues or gaps - solving these can help engineers across your organisation use your tools and platforms more effectively.
Identifying these kinds of gaps and common patterns can be greatly facilitated by building into the process, or the template, ways to quickly surface this data. That could be done by hosting all your PRRs – or at least their final report – in a single place, and using tags on the document. Or, as part of the report itself, signaling the areas where improvement was needed in that PRR. Automation could then process those files, read the tags, and easily identify the most common issues.
PRRs, like any other initiative, can fail. One major reason is a lack of buy-in. A PRR is ideally connected to some sort of event (new launch, redesign, high stakes business event). This will ensure focus from the development team, and that they will have time to work on it. Running a PRR without any specific goal means that the PRR can drop to the bottom of the development team’s priority list. If this is the case, it will help considerably to have buy-in from the team’s management, and a commitment to allocate resources to complete the PRR.
If the development team feels threatened by the review, or that the team itself is under review, they can go on the defensive, and actively hide any potential risk in the system to avoid ‘failing’ the review. Make sure the message that you are there to help the team is passed along in a clear manner.
Finally, the work involved in filling in the PRR template needs to be acceptable to the development team. Keep the template current, relevant, usable, and no more complex than absolutely necessary. Listen to the feedback from the teams to understand what could be improved. Find ways to automate fetching the answers to some of the questions (e.g. automatically listing dashboards for the services included in the review). This will not only speed up the process, but make filling out the template less of a boring task for the development team.
In many organisations, SRE time is scarce and demand for production expertise is high. Running PRRs is a structured way to scale that production expertise. PRRs are most obviously intended as a way for the reviewing team (normally SRE or a similar role focused on production excellence) to help developers proactively spot problems and gaps and to create strategies to improve the reliability of their services. However, in addition to that, PRRs provide the reviewing team with invaluable data about how engineering teams are working with existing infrastructure, tools, and processes; and what common operational problems and gaps exist. PRRs are thus also a critical feedback loop between development teams and those who shape the infrastructure, platforms, tools, documentation, and processes which development teams use.
